「Rust Atomics and Locks」を読んだ
2023-02-05
発売前からすごく楽しみにしていた本で、発売日に買って年末から一生懸命読んでいた。
今なら以下から無料で読める。
内容としては求めるものが分かりやすく書かれており、すでに2023 年に読んで良かった本の1つに入りそう。
目次
書籍を通して得たかった知識
例えば以下のようなコードを書いた際に、println!でどのような数値のペアが表示されるのか。結論から書くと0 0,10 20といった値がまずは思い浮かぶと思うが、0 20というペアで表示される可能性もあるとされており、その際以下のような疑問・不明点があった。
0 20と表示になるのはどのような条件で何が起こった場合なのか強いメモリモデルとされるx86でも0 20というペアは発生するのか- 本ケースにおいて
x86ではどのような機械語が吐かれるのか Store buffers,Invalidation queues,及びそれらのタイミングは以下のコードにどう影響を与えるのかx86において上記の影響を回避するにはどうしたら良いのか0 20と表示されるケースをなくすにはOrderingをどうすればよいか
この書籍では上記が分かるようになっている。言い換えると同様の疑問を持っている方はこの書籍を読むことで得られるものがあるかもしれない。
use std::{sync::atomic::{AtomicI32, Ordering::Relaxed}, thread};
static X: AtomicI32 = AtomicI32::new(0);
static Y: AtomicI32 = AtomicI32::new(0);
fn a() {
X.store(10, Relaxed); // (1)
Y.store(20, Relaxed); // (2)
}
fn b() {
let y = Y.load(Relaxed); // (3)
let x = X.load(Relaxed); // (4)
println!("{x} {y}");
}
fn main() {
thread::scope(|s| {
s.spawn(|| {a(); });
s.spawn(|| {b(); });
})
}
上記の内容はChapter3,Chapter7に集約されており、それらの章をピックアップして読んで見ても良さそう。
また、自分の興味がたまたま上記のように偏っているが、Arc,Channelsを実装していく章もあるので、上記を理解しているからと言って楽しめないわけではないと思う。
Concurrency の基礎や Atomics について
序盤は Concurrency の基礎や Atomics についての説明がされている。
たとえばScoped threadsの話であったりInterior Mutability, Send, Syncの説明と言った感じだ。
その後にAtomic変数のusecaseについての説明が続く。
この中でも以下のようなケースでMutexGuardの生存期間がif letの完了までなので気をつけましょう。という話が印象に残っている。
if let Some(item) = list.lock().unwrap().pop() {
process_item(item);
}
このあたりは基本的な話も多いので分かっている方は流す程度でもいいのかもしれない。自分は知らないことも多かったが。
Memory Ordering
Chapter3ではMemory Orderingについて書いてあり、自分が最も関心のある章。冒頭の疑問のうちいくつかの答えを示している章でもある。
高速化のためコンパイラやアウトオブオーダー実行によるreorderingについての話からはじまり、それをどう制御していくかの話につながっていく。ジョークっぽく書かれてはいるが以下がOrderingの実態なんだな。というのが伝わってきてよかった。
let x = a.fetch_add(1,
Dear compiler and processor,
Feel free to reorder this with operations on b,
but if there's another thread concurrently executing f,
please don't reorder this with operations on c!
Also, processor, don't forget to flush your store buffer!
If b is zero, though, it doesn't matter.
In that case, feel free to do whatever is fastest.
Thanks~ <3
);
その後Happens-Before Relationshipの話へとつながっていく。自分はHappens-Before Relationshipのことはこの本を読むまで知らず今回知ることができて本当に良かったと思っている。
冒頭の疑問にある0 20の話はHappens-Before Relationshipを用いるととてもわかり易いことがわかった。
static X: AtomicI32 = AtomicI32::new(0);
static Y: AtomicI32 = AtomicI32::new(0);
fn a() {
X.store(10, Relaxed); ①
Y.store(20, Relaxed); ②
}
fn b() {
let y = Y.load(Relaxed); ③
let x = X.load(Relaxed); ④
println!("{x} {y}");
}
基本的なルールとして同じスレッド内では記述した順で発生する。となっているので ①->②,③->④ のHappens-Before Relationshipが発生する。
その場合出力としてイメージしやすいのはまず0 0,10 20。また③①②④ となった場合に10 0となるのもイメージできる。しかし、冒頭に書いたように0 20のケースもありうると書かれており、これは ①②-③④ 間にHappens-Before Relationshipが発生していないためとされている。③ が仮に20であっても ①->③ のHappens-Before Relationshipがないため ④ で0になる可能性がある。
0 20というケースをなくすには ①->③ のHappens-Before Relationshipを形成してやる必要があり、Release and Acquire Orderingを使用してHappens-Before Relationshipを形成する話に続いていく。自分の理解だと、具体的には以下ようにすることで①->②->③->④のHappens-Before Relationshipが形成されると理解している。
Acquireによって後続のstoreが③より前倒しになることはないし、Releaseにより後続のloadが②より後回しになることがないからだ。
static X: AtomicI32 = AtomicI32::new(0);
static Y: AtomicI32 = AtomicI32::new(0);
fn a() {
X.store(10, Relaxed); ①
Y.store(20, Release); ②
}
fn b() {
let y = Y.load(Acquire); ③
let x = X.load(Relaxed); ④
println!("{x} {y}");
}
この辺はもう一例挙げられており図と合わせて見るとわかりやすかった。
use std::sync::atomic::Ordering::{Acquire, Release};
static DATA: AtomicU64 = AtomicU64::new(0);
static READY: AtomicBool = AtomicBool::new(false);
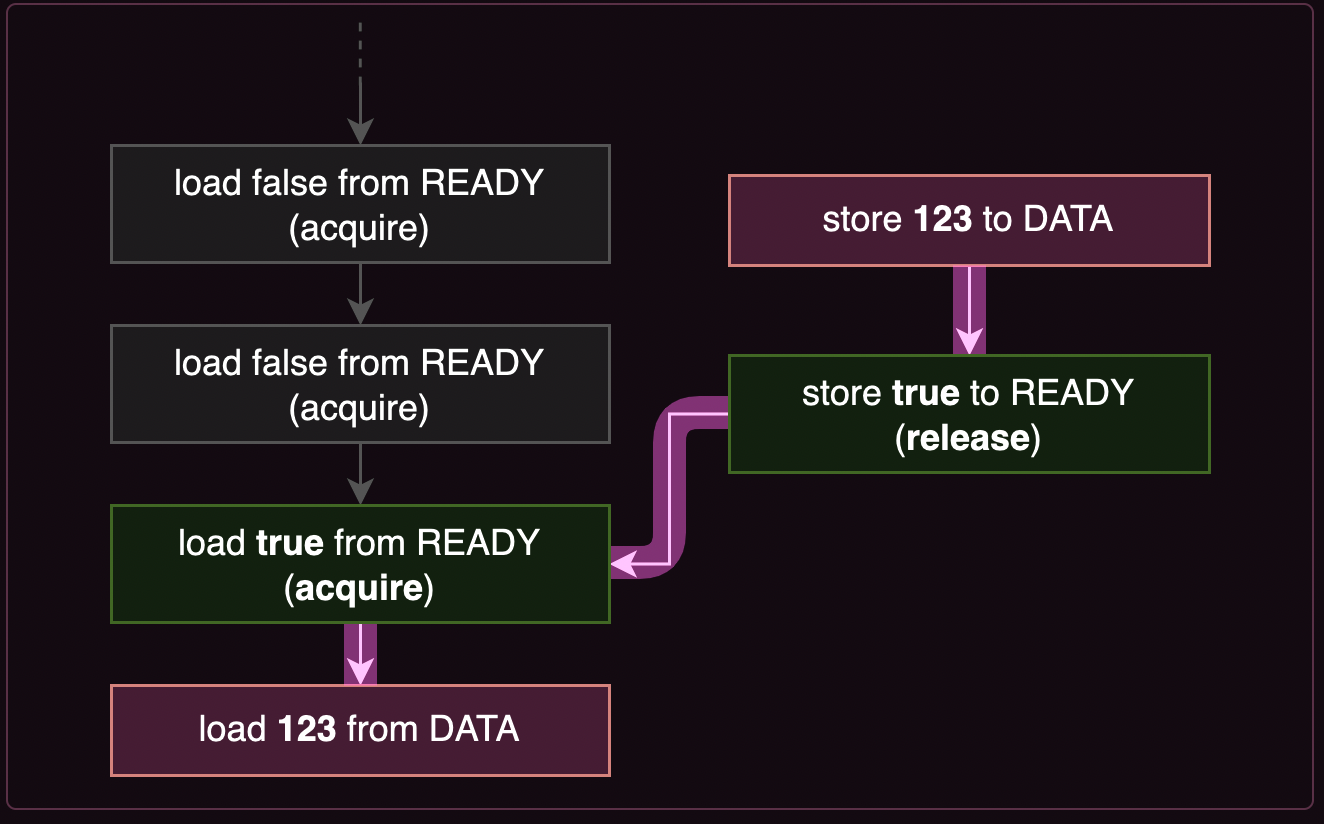
fn main() {
thread::spawn(|| {
DATA.store(123, Relaxed); // ①
READY.store(true, Release); // ② Everything from before this store ..
});
while !READY.load(Acquire) { // ③.. is visible after this loads `true`.
thread::sleep(Duration::from_millis(100));
println!("waiting...");
}
println!("{}", DATA.load(Relaxed)); // ④
}
READY.store(true, Release)とREADY.load(Acquire)によってHappens-Before Relationshipが形成され、①->④の関係も形成されるというのが自分の理解だ。
このあとはいくつかの例とSequentially Consistent OrderingやFencesの話が続く。 そもそも自分はstd::sync::atomic::fenceの存在を知らなかったし、どう使い分けるのかわかっていなかったのが面白い例が示されていた。
①の箇所でload(Acquire)するのではなく②の位置でfence(Acquire)するというものだ。こうすれば③においてHappens-Before Relationshipは形成されているし、readyになるまでコストの高いAcquireを呼ぶのではなくRelaxedで良くなる。
use std::sync::atomic::fence;
static mut DATA: [u64; 10] = [0; 10];
const ATOMIC_FALSE: AtomicBool = AtomicBool::new(false);
static READY: [AtomicBool; 10] = [ATOMIC_FALSE; 10];
fn main() {
for i in 0..10 {
thread::spawn(move || {
let data = some_calculation(i);
unsafe { DATA[i] = data };
READY[i].store(true, Release);
});
}
thread::sleep(Duration::from_millis(500));
let ready: [bool; 10] = std::array::from_fn(|i| READY[i].load(Relaxed)); // ①
if ready.contains(&true) {
fence(Acquire); // ②
for i in 0..10 {
if ready[i] {
println!("data{i} = {}", unsafe { DATA[i] }); // ③
}
}
}
}
その後読みすすめる中で見つけた気になるキーワードとしてOut-of-Thin-Air Valuesがある。ぱっと調べた感じではよくわからなかったので時間ができたら改めて調べてみたい。
Chapter3の最後にまとめられている「よくある誤解」もとても良くてMyth: I need strong memory ordering to make sure changes are "immediately" visible.のようなものが誤解としていくつか挙げられている。
その中でもMyth: Sequentially consistent memory ordering is a great default and is always correct.は自分がこの書籍を読む以前に思っていた内容なので興味深い。ちなみにここでは、パフォーマンスの観点を除いた上で「SeqCstは何か複雑なことが起こっているか、作者がメモリの順序に関する仮定を分析する時間をとっていない可能性があるため注意しろ」と書いてある。
この書籍を読んだあとであれば言いたいことは理解できるし、パフォーマンスの観点を加味しSeqCst時にCPUがどのようなことを行うのかイメージするとなおさらではあるのだが、自分はこの域に達していないし、安全方向に倒したいよね。という気持ちが半分くらいある。
この内容についてみんながどう思ったのかは聞いてみたくある。
Spin Lock, Channels, Arc
Chapter4からChapter6でSpin Lock, Channels, Arcを自作する章が続いていく。Chapter3の内容を理解できいていれば、そこまで難しい内容はなかったように記憶している。 が、自分の関心がChapter3,Chapter7によりすぎていたのと、読んでからこの記事を書くまでに時間が空いているというのあり、Chapter 6. Building Our Own "Arc"を中心に時間をとって読み直そうとは思っている。
Understanding the Processor
Chapter7ではUnderstanding the Processorとして実際にx86でやarmでどうなるかを解説してくれている。
これによりChapter3でHappens-Before Relationshipという概念をもとに考えればいいことはわかったが、実際にx86やarmではどうなってるんだ。というのが分かるようになる。
ただ後述するが、この章だけ読んでもイメージができず「プログラマーのためのCPU入門」をあわせて読むことでようやく理解できた箇所がある。「プログラマーのためのCPU入門」の第11章 メモリ順序付けはとてもおすすめだ。
この章には冒頭の疑問の以下についての記述がある
強いメモリモデルとされるx86でも0 20というペアは発生するのかx86ではそれぞれどのような機械語が吐かれるのかStore buffers,Invalidation queues,及びそれらのタイミングは以下のコードにどう影響を与えるのかx86において上記の影響を回避するにはどうしたら良いのか
pub fn a(x: &AtomicI32) {
x.store(0, Release);
}
pub fn b(x: &AtomicI32) -> i32 {
x.load(Acquire)
}
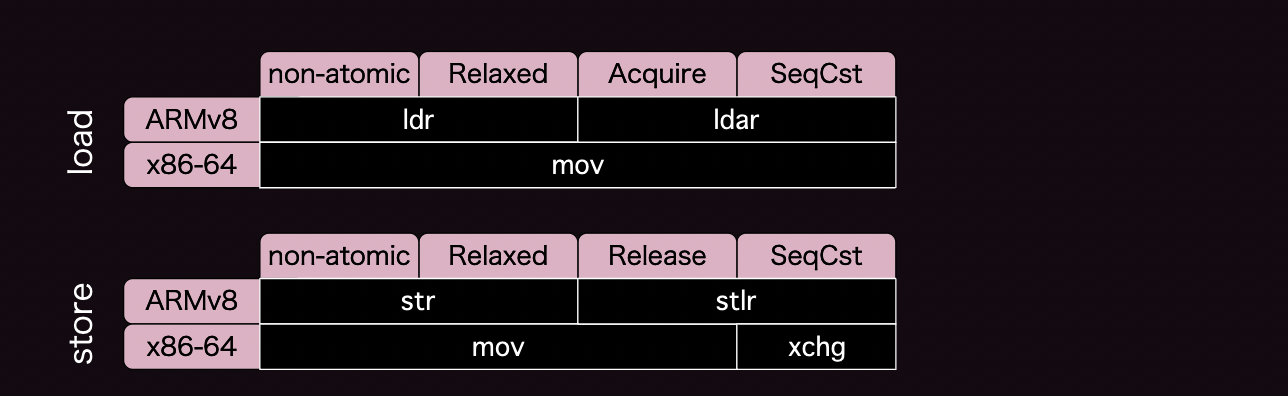
上記Rustのコードはx86-64ではそれぞれ以下のような機械語となることが書かれている
a:
mov dword ptr [rdi], 0
ret
b:
mov eax, dword ptr [rdi]
ret
これを読んだ直後はx86がどういったReorderを行うかStore Buffersがどう影響するのかが理解できていなかったためlockやfenceが現れない理由がわからなかった。
しかし、この点に関しては「プログラマーのためのCPU入門」とIA-32 インテル® アーキテクチャ ソフトウェア・デベロッパーズ・ マニュアルをあわせて読むことで理解できた気がする。
「プログラマーのためのCPU入門」表11.1にはx86において入れ替えが不可能なケースは先行ロードと後続ロード、先行ストアと後続ストア、先行ロードと後続ストア、逆に可能なケースは先行ストアと後続ロードであると。また以下のようにも書いてある。
全体を高速化するために、滞留中のストアバッファから本体への書き込み処理を待たずに読み出しアクセスを先に処理します。....このケースはメモリアクセ順序の入れ替えに慎重なx86においても発生します
プログラマーのためのCPU入門 p183より
またIA-32 インテル® アーキテクチャ ソフトウェア・デベロッパーズ・ マニュアルにも以下のようにある。
インテル® Pentium® プロセッサおよびIntel486™プロセッサは、「プロセッサ・オーダリング」と定義されるメモリ・オーダリング・モデルを使用するが、ほとんどの状況ではストロング・オーダリング・プロセッサとして動作する。システムバスでは、読み取りと書き込みは常にプログラムされた順序で実行されるが、次のような場合には、プロセッサ・オーダリングが行われる。バッファリングされた書き込みがすべてキャッシュ・ヒットで、読み取りミスによってアクセスされるアドレスに指定されない場合は、システムバス上でバッファリングされている書き込みよりも先に読み取りミスを実行できる。
IA-32 インテル® アーキテクチャ ソフトウェア・デベロッパーズ・ マニュアルより
つまりx86においてはStore Buffersの反映タイミングにより先行ストアと後続ロードの入れ替えは発生しうるが、その他の入れ替えが発生しないため、lockやfenceを使用しなくとも(atomics and locksでは"for free"と表現している)release and acquire semanticsを手に入れられると書いてある。
結果x86ではRelaxed loadとAcquire load, Relaxed storeとRelease storeは同じ機械語となる。
しかしSeqCstの場合は先行ストアと後続ロードの入れ替えを考慮しないと行けないのでstoreの場合だけlockやfenceが必要とある。
pub fn a(x: &AtomicI32) {
x.store(0, SeqCst);
}
a:
xor eax, eax
xchg dword ptr [rdi], eax
ret
IntelのマニュアルによるとXCHG 命令は、LOCK 接頭辞の有無にかかわらず、常に LOCK# 信号をアサートします。とあるためxchgによって先行ストアと後続ロードの入れ替えは発生せず、シーケンシャルに実行されるのだと理解した。
x86ではそれぞれどのような機械語が吐かれるのかの解でもあるが上記をまとめると、以下のような対応となる。(以下の対応表はChapter7末に掲載されている。)
OS PrimitiveとFutex
以降はOSのPrimitiveな機能を紹介しつつ、Futexの話に移っていく。manでは以下のように記載されている。
futex() システムコールは、 指定したアドレスの値が変更されるのをプログラムが待つ手段や 特定のアドレスに対して待機中のプロセスを wake (起床) させる手段を提供する (プロセスが異なれば同じメモリーに対するアドレスも同じではないかもしれないが、 カーネルは異なる位置にマップされた同じメモリーを futex() で使えるよう内部でマップする)。 通常は、このシステムコールは futex(7) に書かれているように、 共有メモリー中のロックが競合する場合の処理を実装するのに用いられる。
またFUTEX_WAITは以下のように書かれている
この操作は futex アドレス uaddr に指定された値 val がまだ格納されているかどうかを不可分操作で検証し、 sleep 状態で この futex アドレスに対して FUTEX_WAKE が実行されるのを待つ。 timeout 引き数が NULL でない場合、その内容は待ち時間の最大値を表す (この停止時間はシステムクロックの粒度に切り上げられ、 カーネルのスケジューリング遅延により少しだけ長くなる可能性がある)。 NULL の場合、 呼び出しは無限に停止する。 引き数 uaddr2 と val3 は無視される。
例えば以下のようにあるメモリが期待する値であるうちはsleepし、メモリの値を変更しFUTEX_WAKEすることで起床させることができるようだ。また、状態をユーザ側で起床に関する状態を持っているためブロックする場合以外はカーネルに依存せずスキップするなど制御が可能なため高速である。と書かれているように見える。
let a = AtomicU32::new(0);
thread::scope(|s| {
s.spawn(|| {
thread::sleep(Duration::from_secs(3));
a.store(1, Relaxed);
wake_one(&a);
});
println!("Waiting...");
while a.load(Relaxed) == 0 {
wait(&a, 0);
}
println!("Done!");
});
そしてChapter 9ではFutexを用いてLockを実装していく。
ここも一通り読んだのだが、すでに忘れっつつあるのと、手を動かせてはいないのでChapter 6と合わせていつか振り返りたい。
ここまでが一通り読んだ記録や感想だ。
現時点でいくつかTODOもあるので以下に記載しておく
Out-of-Thin-Air Valuesについてもう少し調べてみる「プログラマーのためのCPU入門」にメモリ領域や命令種別の混在によっては表11.1で不可となっている組み合わせにおいてもメモリアクセスが入れ替わる可能性がありますという記述についてもう少し調べてみるChapter 6,Chapter 9について実際にもう少し手を動かしてみる
以上。